

btw – kod może Cię zaskoczyć!
Spis treści
- Wprowadzenie
- QuerySelector/querySelectorAll
- Dlaczego querySelector jest lepszy od innych metod?
- Podsumowanie
Wprowadzenie
Lat temu bardzo dużo główną przewagą jQuery nad czystym JS było to, że ujednolicała i upraszczała zachowanie pomiędzy przeglądarkami. JS jednak zaczął nadrabiać stracone lata, modernizując swoje API, większy nacisk również został położony na kompatybilność między przeglądarkami.
Jedną z rzeczy które najbardziej lubię w jQuery jest możliwość używania selektorów do pobierania elementu, np $('.form .element:not(.inactive)').
I choć JavaScript od wielu lat daje możliwość używania selektorów przy pobieraniu elementów DOM za pomocą querySelector/querySelectorAll, bardzo często widzę użycia innych metod pobierania elementów, jak getElementById czy getElementsByTagName.
W tym wpisie będę chciał przekonać Cię, że querySelector/querySelectorAll to zdecydowanie lepszy wybór 🙂
QuerySelector/querySelectorAll
Kilka słów o querySelector
Metoda ta zwraca pierwszy element pasujący do selektora.
Zwrócony element jest typu Element, interfejs ten udostępnia m.in metody:
- closest, która zwróci pierwszego rodzica pasującego do selektora
- animate, pozwalającą utworzyć oraz uruchomić animację na wybranym elemencie
- requestFullscreen, która pokaże wybrany element na pełnym ekranie
Istotnym elementem jest to, że metody querySelector i querySelectorAll można uruchamiać również na obiekcie typu Element – co spowoduje wyszukanie po danym selektorze wewnątrz wybranego elementu. Wiąże się z tym pewna nieścisłość – ale o tym dalej.
Słówko o querySelectorAll
Ponieważ querySelector zwraca tylko pierwszy pasujący element, potrzebujemy metody która zwróci nam wszystkie pasujące elementy. Tą metodą jest querySelectorAll.
Zwraca ona obiekt NodeList – możesz iterować po tym obiekcie jak po tablicy metodą forEach bądź składnią for..of, aczkolwiek jeśli chcesz mieć pełną paletę operacji na tablicach możesz przetransformować obiekt do prawdziwej tablicy:
const array = [...document.querySelector('.items')];
Dwa słowa o pewnej nieścisłości
querySelector pozwala stosować selektory a także przeszukiwać DOM relatywnie w stosunku do elementu, jest jednak jedno „ale”.
Jeżeli przeszukujemy DOM relatywnie spodziewalibyśmy się, że znalezione elementy będą musiały spełniać warunek selektora wewnątrz elementu. Brzmi to może dziwnie 🙂 Ale spójrzmy na kod:
<div class="parent">
<div id="element">
<div class="child"></div>
</div>
</div>
Mając taki kod JS:
const element = document.querySelector('#element');
const child = element.querySelector('.parent .child');
Spodziewałbym się zwrócenia wartości null, ponieważ w divie o id element nie ma elementu z klasą child wewnątrz elementu z klasą parent.
Co zaskakujące jednak, zostanie zwrócony div z klasą child – ponieważ domyślnie cała hierarchia DOM jest brana pod uwagę.
Może to być uznane za nienaturalne – jak więc uzyskać naturalne zachowanie? Poprzez dodanie do selektora pseudoklasy :scope.
Spójrzmy na taki kod HTML:
<div class="parent">
Parent
<div class="child child-1">
Child outer
<div class="child child-2">
Child inner
<div class="child child-3">
Child
<div class="parent child-1">
Child but also a parent
<div class="child child-2">
Child
</div>
</div>
</div>
</div>
</div>
</div>
Powtarza się tam selektor .parent .child, który będziemy chcieli sprawdzić.
Stworzymy selektor który będzie miał formę albo
':scope .parent .child'
I ten selektor będzie sprawdzany tylko w hierarchii wewnątrz elementu, oraz selektor z zachowaniem domyślnym:
'.parent .child'
Elementem w stosunku do którego będziemy przeszukiwać dom będzie element z tekstem Child outer. Kliknięcie na przycisk będzie wywoływać funkcję, która do pasujących elementów dodawać będzie czarne tło:
const child1 = document.querySelector('.child-1');
document.querySelector('#select').addEventListener('click', () => {
const scoped = document.querySelector('#scoped').checked;
const selector = `${scoped ? ':scope ' : ''}.parent .child`;
const elements = [...child1.querySelectorAll(selector)];
elements.forEach(element => element.classList.add('black'));
});
Jaki będzie efekt dla wywołania funkcji bez zaznaczonego checkboxa scoped? Zaznaczonych zostanie wiele elementów, ponieważ pod uwagę wzięta będzie klasa parent będąca poza elementem w stosunku do którego szukamy:
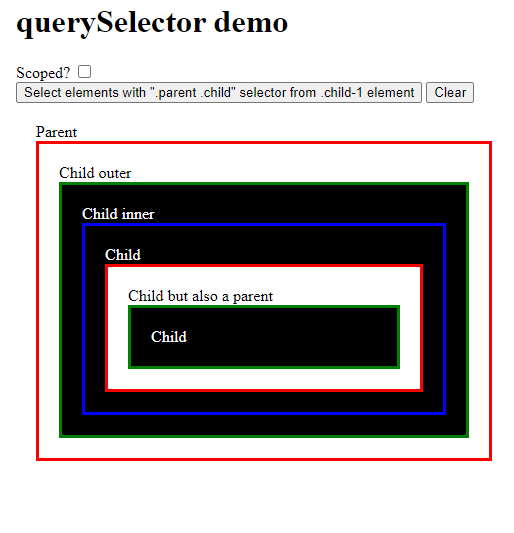
Natomiast gdy zaznaczymy checkbox zaznaczy się tylko jeden element:
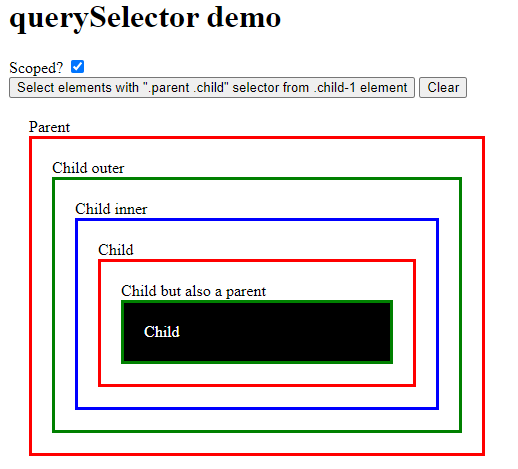
Ponieważ dodana pseudoklasa wymusza branie pod uwagę tylko hierarchię wewnątrz elementu.
Kod przykładu na Github
Pełny kod przykładu można znaleźć pod adresem:
https://github.com/radek-anuszewski/queryselector-scope-demo
Klikalny przykład na Github Pages
Możesz przeklikać przykład pod adresem:
https://radek-anuszewski.github.io/queryselector-scope-demo/index.html
Dlaczego querySelector jest lepszy od innych metod?
Moim zdaniem oczywiście 🙂 A więc czemu tak uważam?
Po pierwsze, mamy bardziej czytelne i jednorodne API. Istnieje jedna metoda zamiast kilku:
- getElementById
- getElementsByClassName
- getElementsByTagName
Pierwsza z powyższych zwraca pojedynczy element – co jest oczywiście logiczne biorąc pod uwagę, że id powinno być unikalne, pozostałe 2 zwracają listę elementów.
Uważam że zachowanie querySelector i querySelectorAll jest czytelniejsze – chcesz pierwszy pasujący do selektora element? Użyj tego pierwszego. Chcesz listę elementów? Użyj drugiego.
Używanie selektorów pozwala nam reużywać wiedzy którą nabyliśmy przy nauce / pracy w CSS. I odwrotnie – jeśli poznajemy selektory pod kątem metody querySelector wiedza ta będzie mieć również zastosowanie przy stylowaniu aplikacji.
No i najważniejsze na koniec, coś co jest oczywiste – selektory 🙂 Dzięki temu, bez konieczności użycia jQuery bądź innej biblioteki czy konieczności odfiltrowywania elementów w kodzie, możemy bardzo szczegółowo przeszukiwać DOM.
Podsumowanie
Oczywiście dużą rolę w wyborze sposobu odpytywania DOM będą odgrywać osobiste preferencje. Niektórzy uznają dedykowane metody za lepsze – jako bardziej ekspresyjne niż querySelector, którego nazwa na pierwszy rzut oka niewiele mówi.
Osobiście uważam, że querySelector ma znacznie większe możliwości niż inne metody a także jest bardziej minimalistyczna. Zamiast 3 metod mamy 2, które dodatkowo używają zasad znanych z CSS – dlatego myślę, że powinny być preferowanym sposobem dostępu po DOM.

Jeden komentarz do “Poznaj querySelector i przestań używać getElementsBy…”
Możliwość komentowania została wyłączona.